03Pure Python + Evaluation
RAG Engine
A retrieval-augmented generation pipeline with grounded structured output, provider-agnostic models, and a real evaluation harness.
PythonLangChainQdrantPydanticRagas-ready
The problem
LLMs hallucinate and can't answer questions about private documents. Answers must be grounded in retrieved context, and quality must be measured, not assumed.
What it proves
Hard AI engineering: retrieval, structured generation, rate-limit handling, and evaluation with correctness / faithfulness / abstention metrics.
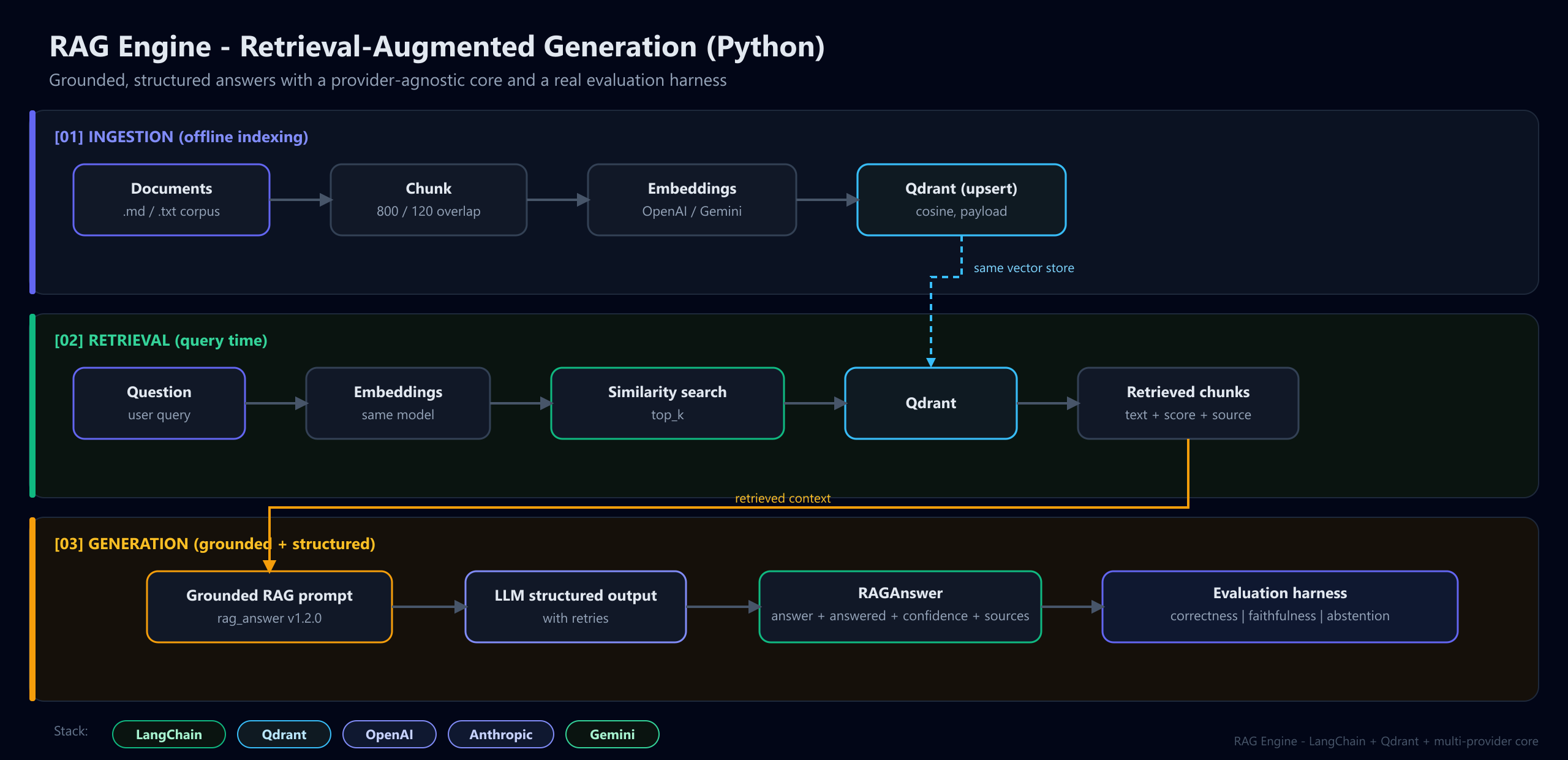
Architecture
- 1.Documents are chunked (800/120) and embedded into Qdrant
- 2.A question is embedded and the top-k chunks are retrieved
- 3.A grounded prompt forces answers from context, or an explicit 'I don't know'
- 4.Output is a validated object: answer + answered + confidence + sources
- 5.An eval harness scores correctness, faithfulness and abstention on a golden set
Architecture diagram
Engineering highlights
- +Provider-agnostic core: swap OpenAI/Anthropic/Gemini via one env var
- +Structured, grounded output with retries on rate limits
- +Evaluation harness with a golden dataset and LLM-as-judge metrics
Demo
Demo: grounded answer with sources; out-of-scope question abstains.
Demo recording placeholder (add a Loom link or demo.gif)